FES 720 Introduction to R
The Importance of Missing Data
autosize: true
FES720 Intro to R

The witch tapped her broomstick, and _whoosh!_ they were gone
Julia Donaldon. 2003. Room on the Broom
=======
Many reasons for missing data …
-
People do not respond to survey (or specific questions in a survey).
-
Species are rare and cannot be found or sampled.
-
The individual dies or drops out before sampling.
-
Some things are easier to measure than others.
-
Data entry errors.
-
Many others!
=======
… but only 4 distributions of missing data
-
Missingness completely at random
-
Missingness at random
-
Missingness that depends on unobserved predictors
-
Missingness that depends on the missing value itself
========
1. Missingness Completely At Random (MCAR)
Reason
The reason for missingness is totally independent of the predictors and response.
i.e., the probability of missingness is the same for each unit in your sample.
Practice
The data sample with complete cases remains an unbiased sample of the population.
Can analyse these complete cases, but loss of power.
Data rarely MCAR.
=======
2. Missingness At Random (MAR)
Reason
Missingness depends only on other available information (e.g., other predictors).
E.g., different social groups have different response rates to a survey:
if sex, race, education, and age are recorded for all people in the survey, then “earnings” is missing at random if the probability of nonresponse to this question depends only on these other, fully recorded variables.
Practice
The data sample with complete cases is a biased sample of the population.
But, this is ok if the regression controls for all the variables that affect the probability of missingness.
E.g., need to include sex, race, education, and age in the model.
========
3. Missingness Not At Random I (MNAR): depends on unobserved predictors
Reason
Missingness:
-
depends on information that has not been recorded and
-
this information also predicts the missing values,
e.g., if a particular treatment causes discomfort, a patient is more likely to drop out of the study (and ‘discomfort’ is not measured).
Practice
Data sample is biased, therefore you need to explicitly model it. (Or accept bias).
========
4. Missingness Not At Random II (MNAR): depends on the missing value itself
Reason
Missingness depends on the (potentially missing) variable itself
E.g., people with higher earnings are less likely to reveal them.
Censoring occurs when a particular value of information leads to missingess
E.g.,
-
everyone earning >$100k does not respond,
-
lighter weight chicks die before they can be sampled,
-
smaller seeds do not germinate.
Practice
Model the missing data.
Include more predictors.
========
Illustration of the classification for the mechanism of missing data
Red is missing data in the y-variable.
Blue is observed data.
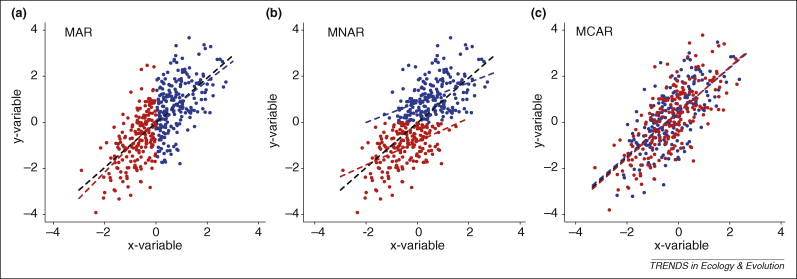
Source: Nakagawa & Freckleton (2008)
(a) Missing At Random
- Missingness depends on x.
(b) Missing Not At Random
- Missingness depends on x and y.
(c) Missingness Completely At Random
- Missingness does not depend on x or y.
=======
Missing data is also philosophical problem
Cannot be sure that data are MCAR, MAR, or MNAR
Because unobserved predictors (lurking variables) are unobserved.
So, we can never rule them out
:(
=======
The best solution to missing data

The best solution to handle missing data is to have none.
– R.A. Fisher
=======
Other solutions to missing data
-
Complete-case analysis
-
Available-case analysis
-
Missingness weighting
-
Imputation
See references for specific details.
=======
What value should I use to indicate missing data?
Principles
Use a value that is:
-
Compatible with (most) software.
-
Unlikely to cause errors in analysis.
=======
What value should I use to indicate missing data?
Practice
| Null values | Problems | Compatibility | Recommendation |
|---|---|---|---|
| 0 | Indistinguishable from a true zero | Never use | |
| Blank | Hard to tell values that are missing from those overlooked on data entry. Hard to tell blanks from spaces (behave differently) | R, Python, SQL | Best option |
| -999, 999 | Not recognized as null by many programs without user input. Can be inadvertently entered into calculations. | Avoid | |
| NA, na | Also an abbreviation (e.g., North America). Can cause problems with data type (turn a numerical column into a text column). NA is more common than na | R | Good option |
| N/A | An alternate form of NA, but often not compatible with software | Avoid | |
| NULL | Can cause problems with data type. Variable use in R | SQL | Good option |
| None | Uncommon. Can cause problems with data type | Python | Avoid |
| No data | Uncommon. Can cause problems with data type. Contains a space | Avoid | |
| Missing | Uncommon. Can cause problems with data type | Avoid | |
| -, +, . | Uncommon. Can cause problems with data type | Avoid |
Table 1 Commonly used null values, limitations, compatibility with common software. From: White et al. 2013
=======
R uses ‘NA’ to indicate missing data
-
When you read data in to R, it will convert blank cells to NA.
-
‘NA’ are the only characters permitted in non-character vectors.
x <- c(1, 2, 3, 4, NA, 6, 7, 8, NA, 10)
x
# [1] 1 2 3 4 NA 6 7 8 NA 10
is.numeric(x)
# [1] TRUE
is.character(x)
#[1] FALSE
=======
Many functions in R have ‘na.rm = ‘ argument
Some functions will fail with missing data.
# generate vector of integers with an NA
x <- c(1:10, NA)
# calculate mean of x
mean(x)
# [1] NA
Include ‘na.rm = TRUE’
mean(x, na.rm = TRUE)
# [1] 5.5
=======
More details
Gelman, A. & Hill J. 2006. Missing data imputation. Chapter 25, In: Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press, UK. pp 529–543.
Nakagawa, S. 2015. Missing data: mechanisms, methods, and messages. In: Fox, Negrete-Yankelevich, and Sosa (eds). Ecological Statistics: Contemporary theory and application. Oxford University Press, UK.
Nakagawa, S. and Freckleton, R.P. 2008. Missing inaction: The dangers of ignoring missing data. Trends in Ecology & Evolution 23, 592–596.